
¿Qué es Hadoop? Introducción a Big Data & Hadoop
Para comprender qué es exactamente Hadoop, primero debemos comprender los problemas relacionados con Big Data y el sistema de procesamiento tradicional. Avanzando, discutiremos qué es Hadoop y cómo Hadoop es una solución a los problemas asociados con Big Data. En el artículo anterior, el tutorial de Big Data, ya discutimos sobre Big Data en detalle y los desafíos con Big Data. En este blog, vamos a discutir:
- Problemas con el enfoque tradicional
- Evolución de Hadoop
- Hadoop
- Hadoop como solución
- ¿Cuándo usar Hadoop?
- ¿Cuándo no usar Hadoop?
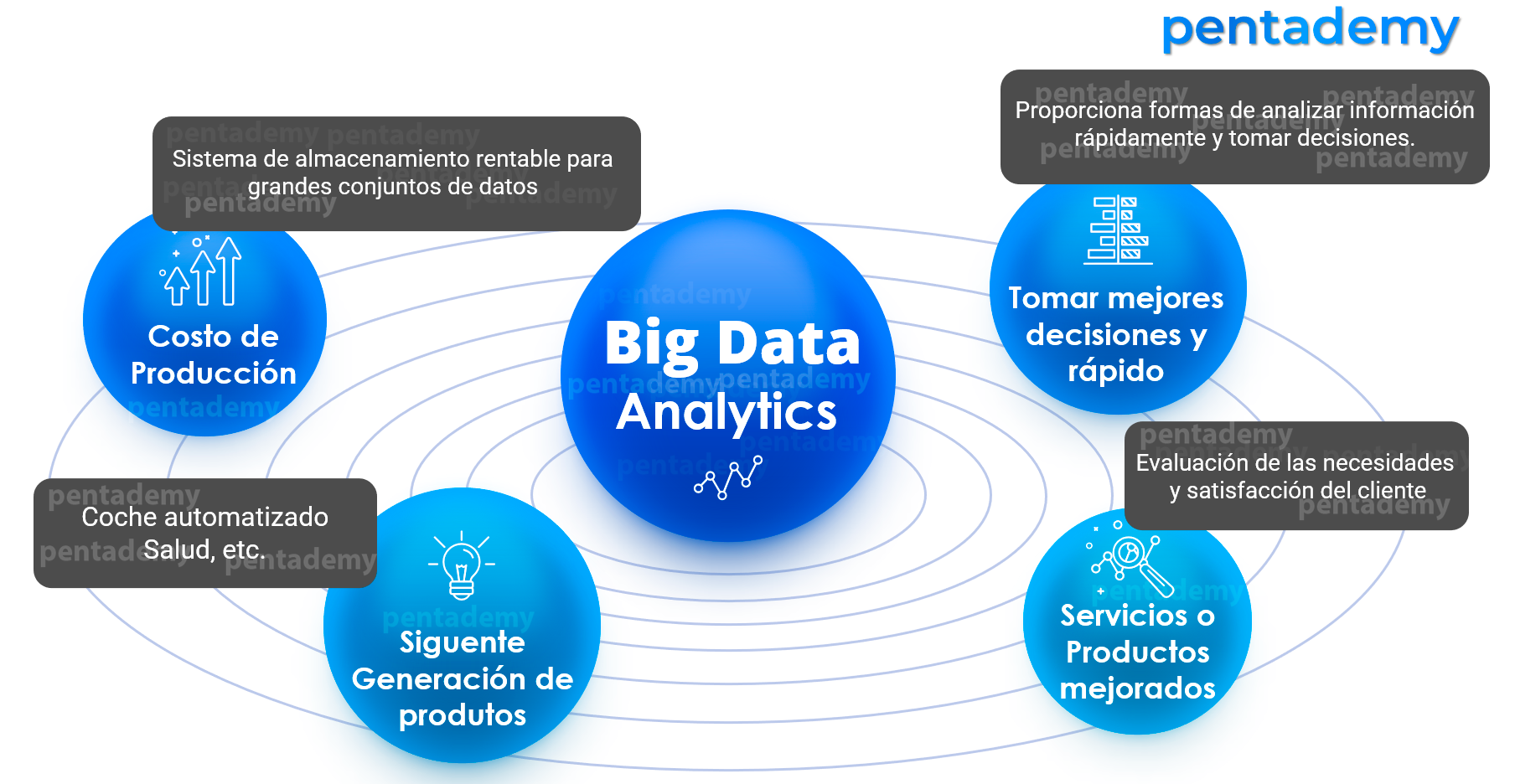
Big Data se perfila como una oportunidad para las organizaciones. Ahora, las organizaciones se han dado cuenta de que están obteniendo muchos beneficios de Big Data Analytics, como puede ver en la siguiente imagen. Están examinando grandes conjuntos de datos para descubrir todos los patrones ocultos, correlaciones desconocidas, tendencias del mercado, preferencias de los clientes y otra información comercial útil. Estos hallazgos analíticos están ayudando a las organizaciones en un marketing más efectivo, nuevas oportunidades de ingresos, mejor servicio al cliente. Están mejorando la eficiencia operativa, las ventajas competitivas sobre organizaciones rivales y otros beneficios comerciales.
Problemas con el enfoque tradicional
En el enfoque tradicional, la cuestión principal era el manejo de la heterogeneidad de los datos, es decir, estructurados, semiestructurados y no estructurados. El RDBMS se centra principalmente en datos estructurados como transacciones bancarias, datos operativos, entre otros y Hadoop se especializa en datos semiestructurados y no estructurados como texto, videos, audios, publicaciones de Facebook, registros, etc. La tecnología RDBMS es un sistema probado, altamente consistente y maduro apoyado por muchas empresas. Mientras que por otro lado, Hadoop está en demanda debido al Big Data, que consiste principalmente en datos no estructurados en diferentes formatos.
Ahora entendamos cuáles son los principales problemas asociados con el Big Data. Para que, avanzando, podamos entender cómo Hadoop surgió como una solución.
El primer problema es almacenar la colosal cantidad de datos.
Almacenar estos enormes datos en un sistema tradicional no es posible. La razón es obvia, el almacenamiento se limitará sólo a un sistema y los datos están aumentando a un ritmo tremendo.
El segundo problema es almacenar datos heterogéneos.
Ahora, sabemos que almacenar es un problema, pero déjame decirte que es sólo una parte del problema. Ya que discutimos que los datos no sólo son enormes, sino que están presentes en varios formatos, así como en: No estructurados, semiestructurados y estructurados. Por lo tanto, usted necesita asegurarse de que, usted tiene un sistema para almacenar todas estas variedades de datos, generados a partir de varias fuentes.
El tercer problema es el acceso y la velocidad de procesamiento.
La capacidad del disco duro está aumentando, pero la velocidad de transferencia de disco o la velocidad de acceso no está aumentando a un ritmo similar. Permítanme explicarles esto con un ejemplo: Si solo tiene un canal de E/S de 100 Mbps y está procesando 1 TB de datos, tomará alrededor de 2,91 horas. Ahora, si tiene cuatro máquinas con un canal de E/S, para la misma cantidad de datos tomará 43 minutos aprox. Por lo tanto, el acceso y la velocidad de procesamiento es el problema más grande que almacenar Big Data.
Antes de entender lo que es Hadoop, veamos primero la evolución de Hadoop durante el período de tiempo.
Evolución de Hadoop
En 2003, Doug Cutting lanza el proyecto Nutch para manejar miles de millones de búsquedas e indexar millones de páginas web. Más tarde en octubre de 2003 – Google publica documentos con GFS (Google File System). En diciembre de 2004, Google publica artículos con MapReduce. En 2005, Nutch utilizó GFS y MapReduce para realizar operaciones. En 2006, Yahoo creó Hadoop basado en GFS y MapReduce con Doug Cutting y el equipo. Te sorprendería que te dijera que, en 2007 Yahoo comenzó a usar Hadoop en un clúster de 1000 nodos.
Más tarde en enero de 2008, Yahoo lanzó Hadoop como un proyecto de código abierto a Apache Software Foundation. En julio de 2008, Apache probó un clúster de nodos 4000 con Hadoop correctamente. En 2009, Hadoop ordenó con éxito un petabyte de datos en menos de 17 horas para manejar miles de millones de búsquedas e indexar millones de páginas web. En diciembre de 2011, Apache Hadoop lanzó la versión 1.0. Más tarde, en agosto de 2013, la versión 2.0.6 estaba disponible.
Cuando estábamos discutiendo sobre los problemas, vimos que un sistema distribuido puede ser una solución y Hadoop proporciona lo mismo. Ahora, entendamos lo que es Hadoop.
¿Qué es Hadoop?
Hadoop es un marco que le permite almacenar primero Big Data en un entorno distribuido, para que pueda procesarlo en paralelo. Básicamente hay dos componentes en Hadoop:
El primero es HDFS para almacenamiento (Hadoop distributed File System), que le permite almacenar datos de varios formatos en un clúster. El segundo es YARN,para la gestión de recursos en Hadoop. Permite el procesamiento paralelo a través de los datos, es decir, almacenados en HDFS.
¿Qué es Hadoop | Introducción a Hadoop | Entrenamiento de Hadoop Pentademy
Entendamos primero hdfs.
HDFS
HDFS crea una abstracción, permítanme simplificarla para usted. Al igual que la virtualización, puede ver HDFS lógicamente como una sola unidad para almacenar Big Data, pero en realidad está almacenando sus datos en varios nodos de forma distribuida. HDFS sigue la arquitectura maestro-esclavo.
En HDFS, Namenode es el nodo maestro y Datanodes son los esclavos. Namenode contiene los metadatos sobre los datos almacenados en los nodos Data, como qué bloque de datos se almacena en qué nodo de datos, dónde se conservan las replicaciones del bloque de datos, etc. Los datos reales se almacenan en nodos de datos.
También quiero agregar, realmente replicamos los bloques de datos presentes en los nodos de datos y el factor de replicación predeterminado es 3. Puesto que estamos utilizando hardware básico y sabemos que la tasa de error de estos hardwares es bastante alta, por lo que si uno de los DataNodes falla, HDFS todavía tendrá la copia de esos bloques de datos perdidos. También puede configurar el factor de replicación en función de sus requisitos. Puede ir a través del tutorial HDFS para conocer HDFS en detalle.
Hadoop como una solución
Entendamos cómo Hadoop proporcionó la solución a los problemas de Big Data que acabamos de discutir.
El primer problema es almacenar Big data.
HDFS proporciona una forma distribuida de almacenar Big Data. Los datos se almacenan en bloques a través de DataNodes y puede especificar el tamaño de los bloques. Básicamente, si tiene 512 MB de datos y ha configurado HDFS de tal forma que creará 128 MB de bloques de datos. Así que HDFS dividirá los datos en 4 bloques como 512/128=4 y los almacenará en diferentes DataNodes, también replicará los bloques de datos en diferentes DataNodes. Ahora, como estamos utilizando hardware de productos básicos, por lo tanto almacenar no es un desafío.
También resuelve el problema de escalado. Se centra en el escalado horizontal en lugar del escalado vertical. Siempre puede agregar algunos nodos de datos adicionales al clúster de HDFS cuando sea necesario, en lugar de escalar verticalmente los recursos de datanodes. Permítanme resumirlo para usted básicamente para almacenar 1 TB de datos, no necesita un sistema de 1 TB. En su lugar, puede hacerlo en varios sistemas de 128 GB o incluso menos.
El siguiente problema fue almacenar la variedad de datos.
Con HDFS puede almacenar todo tipo de datos ya sea estructurados, semiestructurados o no estructurados. Dado que en HDFS, no hay validación de esquemas previos al dumping. Y también sigue a escribir una vez y leer muchos modelos. Debido a esto, solo puede escribir los datos una vez y puede leerlos varias veces para encontrar información.
El tercer desafío fue acceder y procesar los datos más rápido.
Sí, este es uno de los principales desafíos con el Big Data. Para resolverlo, movemos el procesamiento a datos y no a datos al procesamiento. ¿Qué significa eso? En lugar de mover datos al nodo maestro y, a continuación, procesarlos. En MapReduce, la lógica de procesamiento se envía a los distintos nodos esclavos y, a continuación, los datos se procesan en paralelo a través de diferentes nodos esclavos. A continuación, los resultados procesados se envían al nodo maestro donde se combinan los resultados y la respuesta se devuelve al cliente.
En la arquitectura YARN, tenemos ResourceManager y NodeManager. ResourceManager podría o no configurarse en el mismo equipo que NameNode. Sin embargo, NodeManagers debe configurarse en el mismo equipo donde DataNodes está presente.
YARN
YARN realiza todas sus actividades de procesamiento asignando recursos y programando tareas. Tiene dos componentes principales, que son: ResourceManager y NodeManager.
ResourceManager es de nuevo un nodo maestro. Recibe las solicitudes de procesamiento y, a continuación, pasa las partes de las solicitudes a los NodeManagers correspondientes en consecuencia, donde se lleva a cabo el procesamiento real. NodeManagers están instalados en cada DataNode. Es responsable de la ejecución de la tarea en cada DataNode.
Espero que ahora tenga claro lo que es Hadoop y sus principales componentes. Sigamos adelante y comprendamos cuándo usar y cuándo no usar Hadoop.





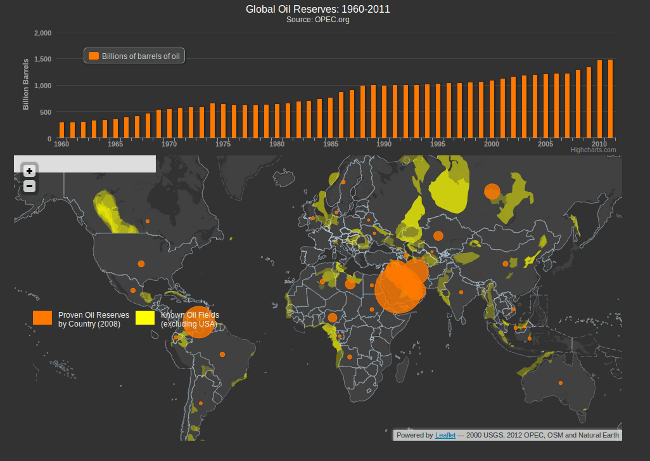






¿Dónde se usa Hadoop?
Hadoop se utiliza para:
- Búsqueda – Yahoo, Amazon, Zvents
- Procesamiento de registros – Facebook, Yahoo
- Almacenamiento de datos – Facebook, AOL
- Análisis de vídeo e imagen – New York Times, similar a los ojos
Hasta ahora, hemos visto cómo Hadoop ha hecho posible el manejo del Big Data. Pero hay algunos escenarios en los que no se recomienda la implementación de Hadoop.
¿Cuándo no usar Hadoop?
A continuación se presentan algunos de esos escenarios:
- Acceso a datos de baja latencia : Acceso rápido a pequeñas partes de datos
- Modificación de datos múltiples: Hadoop es un mejor ajuste sólo si nos preocupa principalmente leer datos y no modificar datos.
- Un montón de archivos pequeños : Hadoop es adecuado para escenarios, donde tenemos pocos archivos pero grandes.
Después de conocer los mejores casos de uso adecuados, sigamos adelante y veamos un caso de estudio donde Hadoop ha hecho maravillas.
Caso práctico Hadoop: CERN
El Gran Colisionador de Hadrones en Suiza es una de las máquinas más grandes y poderosas del mundo. Está equipado con alrededor de 150 millones de sensores, produciendo un petabyte de datos cada segundo, y los datos están creciendo continuamente.
Las investigaciones del CERN dijeron que estos datos han estado aumentando en términos de cantidad y complejidad, y una de las tareas importantes es cumplir con estos requisitos escalables. Por lo tanto, configuran un clúster de Hadoop. Al usar Hadoop, limitaron su costo en hardware y complejidad en mantenimiento.
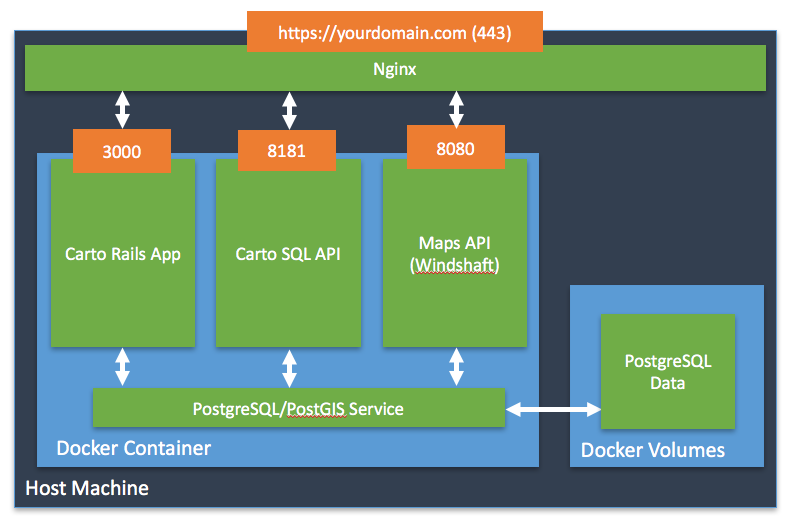
Integraron Oracle & Hadoop y obtuvieron ventajas de integración. Oracle, optimizó su sistema transaccional en línea & Hadoop les proporcionó una plataforma de procesamiento de datos distribuidos escalable. Diseñaron un sistema híbrido y primero movieron datos de Oracle a Hadoop. A continuación, ejecutaron consultas sobre datos de Hadoop desde Oracle mediante API de Oracle. También utilizaron formatos de datos Hadoop como Avro &Parquet para análisis de alto rendimiento sin necesidad de cambiar las aplicaciones de usuario final que se conectan a Oracle.
Los principales componentes de Hadoop que utilizan en el servicio HADOOP CERN-IT:
Puede aprender acerca de cada una de estas herramientas en el blog del ecosistema de Hadoop.
Técnicas para integrar Oracle y Hadoop:
- Exportar datos de Oracle a HDFS
Sqoop fue lo suficientemente bueno para la mayoría de los casos y también adoptaron algunas de las otras opciones posibles como la ingestión personalizada, Oracle DataPump, streaming, etc. - Consultar Hadoop desde Oracle
Accedieron a tablas en motores Hadoop mediante enlaces de base de datos en Oracle. Esto también crea vistas híbridas combinando de forma transparente datos en Oracle y Hadoop. - Utilice marcos de Hadoop para procesar datos en DBs de Oracle
Utilizaron motores Hadoop (como Impala, Spark) para procesar datos exportados desde Oracle y luego leer esos datos en un RDBMS directamente desde Spark SQL con JDBC.
Descarga de Oracle a Hadoop
Paso 1: Descargue datos en Hadoop
Paso 2: Descargar consultas a Hadoop
Paso 3: Acceda a Hadoop desde una consulta de Oracle
Ejemplo de creación de vista híbrida en oracle
create view hybrid_view as select * from online_table where date > '2016-10-01' union all select * from archive_table@hadoop where date <= '2016-10-01'
Sobre la base del caso práctico del CERN, podemos concluir que:
- Hadoop es escalable y excelente para análisis de Big Data
- Oracle está probado para cargas de trabajo transaccionales simultáneas
- Existen soluciones disponibles para integrar Oracle y Hadoop
- Hay un gran valor en el uso de sistemas híbridos (Oracle + Hadoop)
- API de Oracle para aplicaciones heredadas y cargas de trabajo OLTP
- Escalabilidad en hardware de materias primas para cargas de trabajo analíticas
Espero que este blog fuera informativo y un valor añadido a sus conocimientos. En nuestro próximo blog de Tutoriales Hadoop, donde discutiremos sobre Hadoop con más detalle y entenderemos la tarea de los componentes HDFS &YARN en detalle.
Ahora que ha entendido qué es Hadoop, eche un vistazo a la formación Big Data de Pentademy, una empresa especializada en capacitación en Tecnologías de Información (TI) a nivel corporativo e individual, en modalidad presencial, in-house y online. Cuenta con instructores con experiencia empresarial comprobada, experiencia académica, certificados y altamente especializados en los cursos que imparten, lo cual garantiza nuestra calidad de servicio.




Comentarios
Los comentarios han sido cerrados